模型上下文协议(MCP): AI的"USB-C端口"
解决大模型与外部世界的连接问题,实现标准化的数据获取与工具使用
"像USB-C统一了设备连接,MCP统一了AI与外部系统的连接方式"
阅读材料:
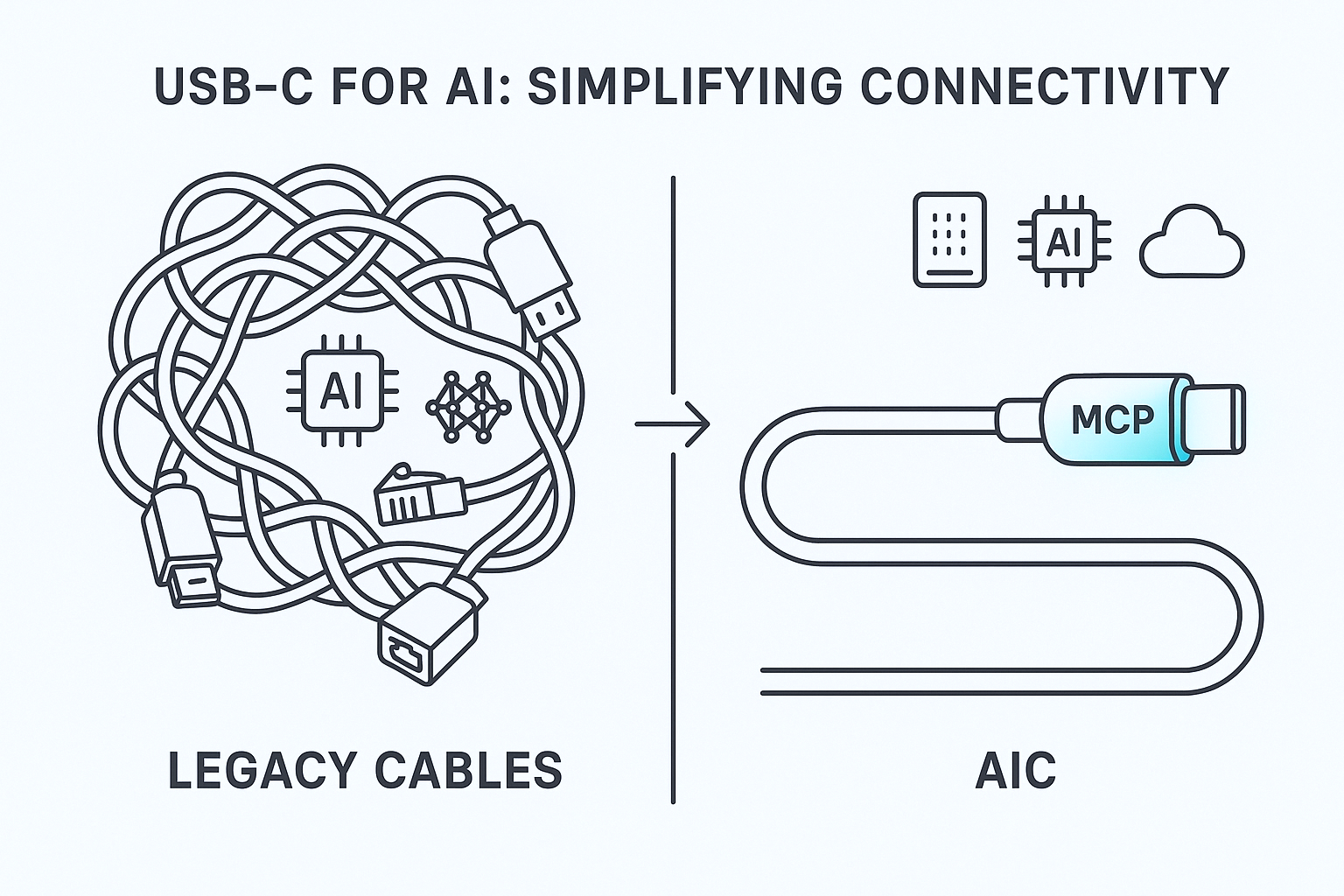
为了解决这些问题,Anthropic公司在2024年末提出了一个大胆的构想:模型上下文协议(Model Context Protocol,简称MCP)。简单来说,MCP试图为AI模型打通与外部世界的连接,充当模型与各种数据源、工具之间的“通用接口”。它的出现引起了业界的强烈关注。一时间,人们把MCP比作人工智能领域的“USB-C端口”——正如USB-C让各种设备可以通过统一标准互联,MCP也旨在提供一种统一标准,将LLM无缝连接到不同的数据源和软件工具上。这一构想如果实现,意味着今后的AI助手不再是封闭的黑盒,而是可以像经验丰富的专家那样,随时引用企业数据库里的资料,调用网络服务获取最新信息,甚至执行操作来更新外部系统。
本文将深度解析Anthropic Claude模型的模型上下文协议(MCP)。我们将从提出背景和设计初衷讲起,阐述MCP的技术架构和它是如何支持大规模上下文管理的;接着比较MCP与现有上下文机制(如GPT模型的Token上下文缓冲、ReAct工具使用等)的异同,探讨MCP在信息组织与引用方面的新思路,以及其性能优化手段;然后结合Claude模型(尤其Claude 3系列)的实际表现,剖析MCP在大模型中的应用效果,包括Claude 3对超长上下文的支持;最后,我们将讨论MCP可能带来的行业影响、当前的局限性,并展望其未来发展趋势。从技术细节到通俗类比,本文力求深入浅出地揭示MCP为何被视作AI发展的重要里程碑,以及它如何让“大模型连接万物”的愿景逐步成为现实。
MCP的诞生:为AI插上“通用接口”
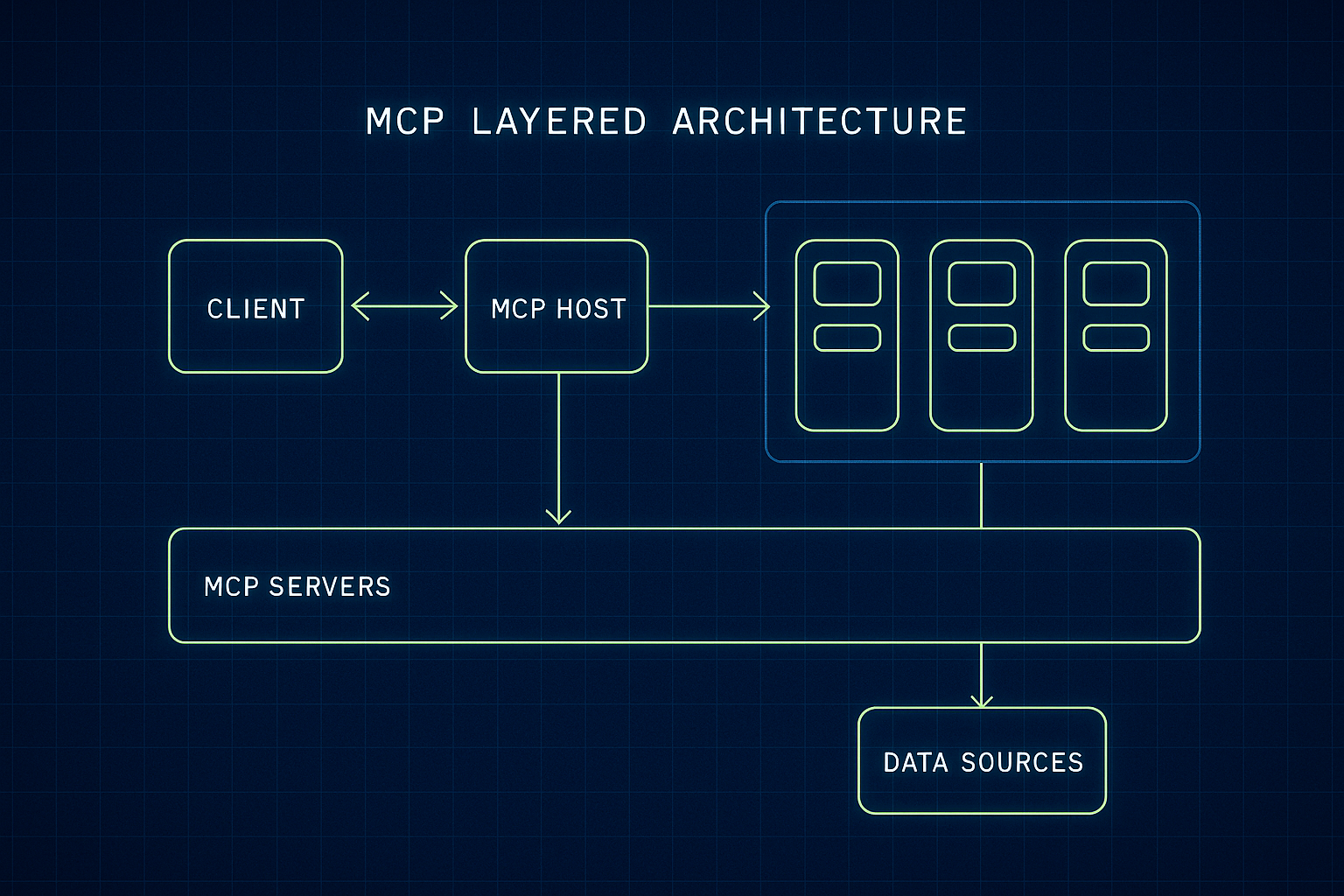
针对上述困境,Anthropic在2024年11月正式开源推出了模型上下文协议(Model Context Protocol, MCP)。它的目标很明确:提供一个通用、开放的标准,彻底取代过去那些零碎不一的集成方式,让AI系统能够以一致的方式接入任意数据源。Anthropic将MCP比喻为AI世界的“USB-C端口”——USB-C让各种设备统一使用一种接口传输数据和电力,同样地,MCP也希望成为AI模型连接外部数据与工具的统一接口。通过MCP,开发者不再需要为每个数据源写定制代码,取而代之的是只要数据源提供MCP兼容的“服务器”,AI应用就能即插即用地连上它,获取所需的信息或执行操作。
MCP背后的理念源自软件工程领域标准化的成功经验。正如数据库访问领域有ODBC/JDBC标准,应用程序只需面对统一接口就能操作不同厂商的数据库;IDE插件领域有Language Server Protocol (LSP)标准,各种编辑器可以通用同一套语言分析服务。Anthropic希望MCP成为AI时代的类似标准,让任何模型(无论Claude、GPT还是开源模型)都能使用任何遵循MCP的工具。这不仅打破了生态壁垒,也使开发者的工作聚焦于“提供能力”本身,而不是围绕不同AI平台重复造轮子。正因如此,MCP被视作一种面向未来的开放基础设施:它不绑定特定厂商或模型,任何人都无需许可即可创建MCP集成。可以说,Anthropic将其开放源代码和规范,也是希望业界广泛参与,将MCP打造为事实上的行业标准。
在MCP推出后的最初几个月里,开发者社区的反响经历了一个有趣的变化:一开始人们只是抱以好奇和观望,“这究竟是什么新玩意?真的有那么革命性吗?”然而随着时间推进,MCP逐渐显示出巨大的潜力。许多主流开发工具开始支持MCP:如程序员使用的Cursor编辑器、Cline、Goose等IDE纷纷宣布适配MCP,让AI编码助手能够直接读取项目文件、查询文档。越来越多的企业应用亦加入进来,早期采用者包括金融支付公司Block(Square)和Apollo等,他们把MCP整合进内部系统,用于构建智能化的AI代理。开发者社区也异常活跃,在短短数月内自发开发了上千个MCP服务器(连接器):截至2025年2月,已有超过1000个社区构建的MCP兼容服务器,可连接各种流行服务。这些服务器覆盖面之广令人惊叹——从Google Drive、Slack聊天、GitHub代码库、SQL数据库,到浏览器控制、设计工具Figma,甚至其他AI服务(如语音合成ElevenLabs)都有人做了MCP封装。MCP由此形成了一个快速扩张的生态圈:支持的工具越多,采用MCP的价值就越大,而采用者越多又进一步刺激开发更多工具接入,如此形成正反馈。短时间内,MCP已从一个新概念成长为炙手可热的话题,被视为构建**“Agentic AI”(自治智能体)**系统所缺失的拼图。越来越多的观点认为,MCP有望成为AI系统连接外部数据的事实标准,就像USB、HTTP这样的通用标准之于各自领域一样。
当然,新事物的崛起也常伴随疑虑。有人质疑MCP是否只是一次噱头,亦或其功能用其他方式也能实现。然而,Anthropic并未“一发布就撒手不管”,而是持续改进MCP并投入开发者教育。2024年底和2025年初,各种技术峰会和研讨中都能见到MCP的身影:Anthropic团队举办研讨会深入讲解MCP原理,公开路线图和示例代码;社区论坛上,开发者们热烈讨论如何实现更好的MCP服务器、分享各自的实践经验……所有迹象表明,MCP正处于一场由点到面的生态构建过程,其影响力与日俱增。
在这样的背景下,我们有必要深入了解MCP的内部机理和设计哲学。这不仅是为了弄清Claude等模型为何能支持超长上下文、无缝访问外部数据,更关系到AI应用开发范式的演进。下一章节,我们将全面剖析MCP的架构与工作方式,看看这个被誉为“AI的USB-C”的协议究竟如何运作,又是怎样解决之前那些棘手的问题的。